Summary of Eugene Yan’s LLM patterns
- Patterns for Building LLM based Systems and products
- Evals
- RAG
- Fine-tuning
- Caching
- Guardrails
- Defensive UX
- Collect user feedback
My summary of the key ideas from Eugene Yan’s excellent LLM patterns blog post: https://eugeneyan.com/writing/llm-patterns/
Patterns for Building LLM-based Systems & Products
Evals
Start by collecting a set of task-specific evals (i.e., prompt, context, expected outputs as references)
Run eval on each prompt update
Metrics:
- Classification: recall, precision
- Lossier reference metrics: ROUGE, BERTScore, MoverScore
Automated evaluation via strong LLM
Less noisy, more biased
GPT4 biases:
- Position bias - 🤖😍 1st position
- Verbosity bias - 🤖😍 longer answers
- Self enhancement bias - GPT4 favours own answers by 10%, Claude-v1 favours own answers by 25%
💡 Eugene Yan’s tips:
- Comparison between 2 solutions better rather than asking for a score
- Vibe eval — eyeball prompts periodically
Retrieval-Augmented Generation (RAG)
Add knowledge to your LLM by retrieving relevant docs and using them to generate answers
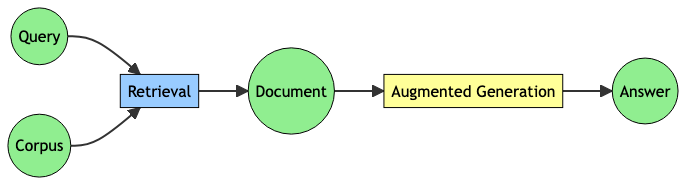
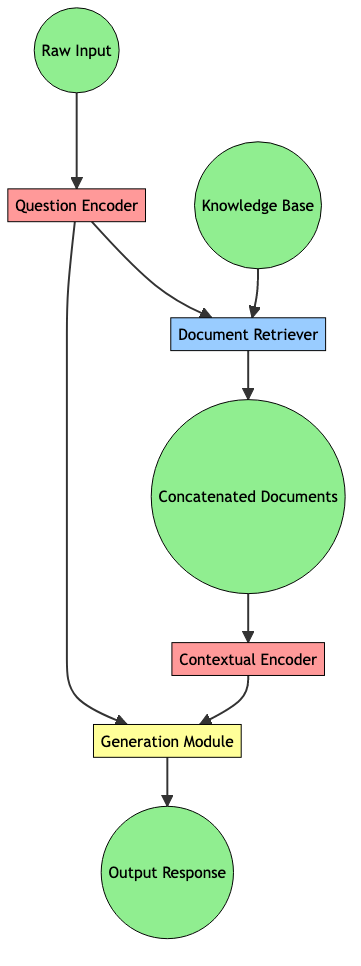
RAG, FiD, RETRO are different RAG architectures requiring aligned query, document embeddings
Document Retrievers
Document retrieval limitations:
☹️ Embedding search poor perf:
- id, person, or object name
- acronym or phrase
- no metadata based filtering, unlike traditional search
- need a vector db
☹️ Traditional search poor perf:
- synonyms (same meaning different words)
- hypernyms (same word different meaning)
💡 Eugene Yan’s tips:
Hybrid retrieval - traditional search index + embedding based search
💡 Without aligned query embeddings and document embeddings use Hypothetical document embeddings
LLM will generate hypothetical document, then retrieve similar documents based on hypothetical
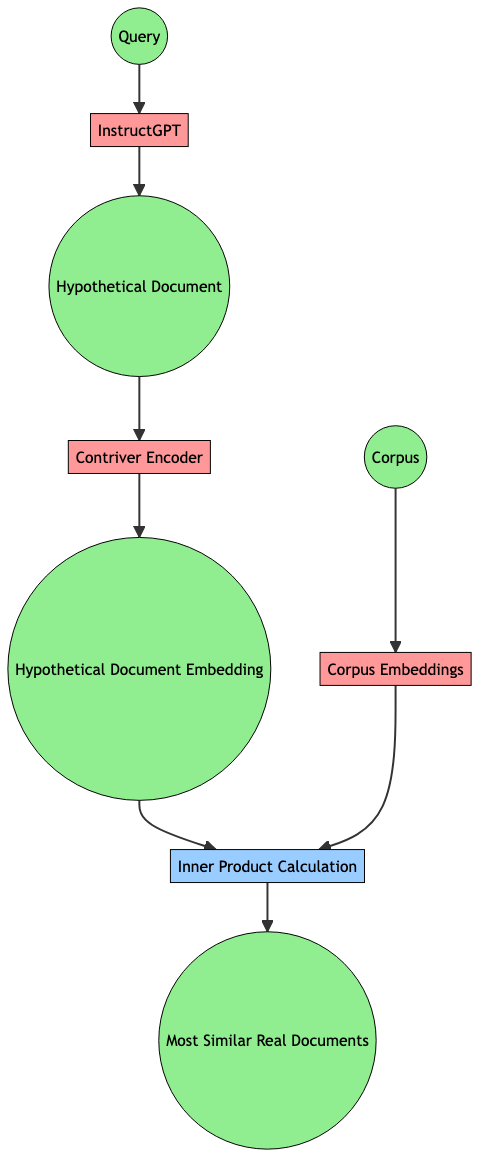
Search engine augmented LMs → ****use Google or Bing search as a document retriever, no need for embeddings
Eugene’s RAG example:
https://eugeneyan.com/writing/obsidian-copilot/
https://github.com/eugeneyan/obsidian-copilot
Fine-tuning
Fine-tuning allows better performance and control
Need significant volume of demonstration data
InstructGPT used 13k instruction-output samples for supervised fine-tuning, 33k output comparisons for reward modeling, and 31k prompts without human labels as input for RLHF.
Instruction fine-tuning: The pre-trained (base) model is fine-tuned on examples of instruction-output pairs to follow instructions, answer questions, etc.
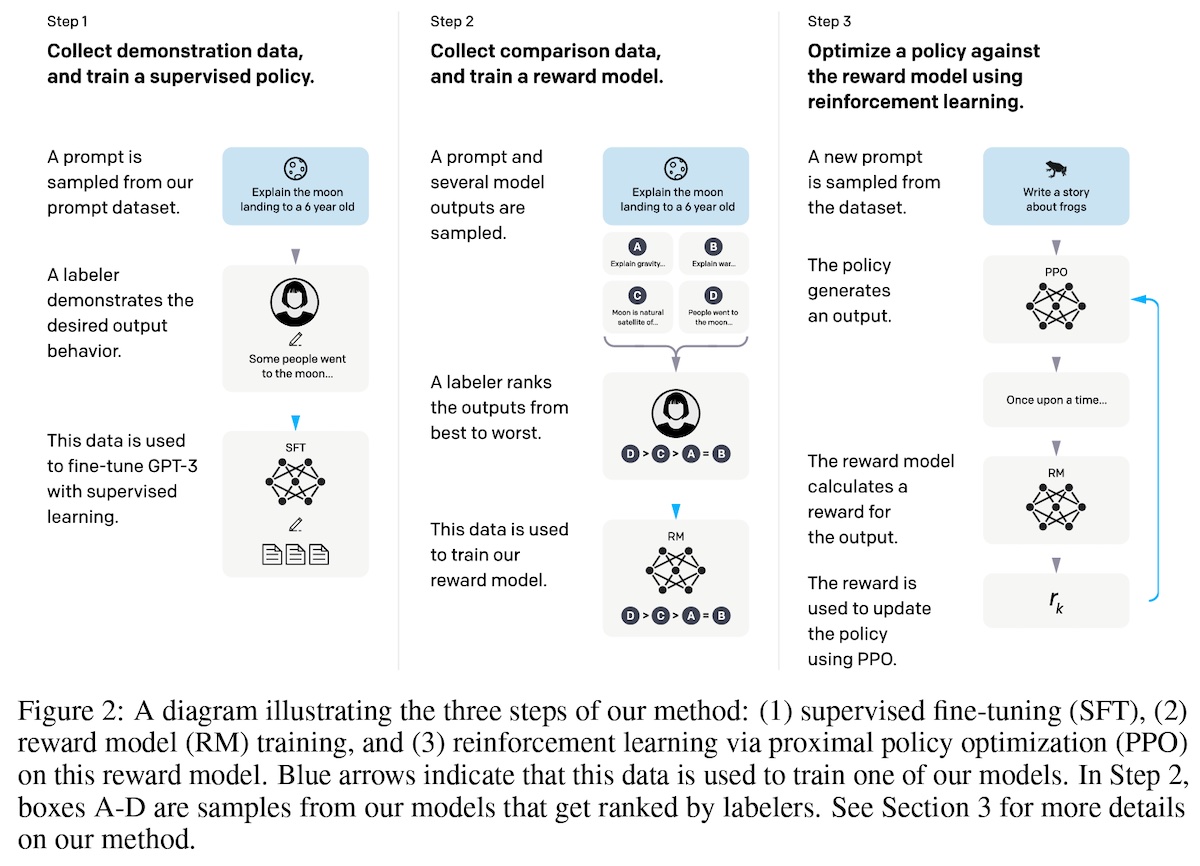 Image source: https://arxiv.org/abs/2203.02155
Image source: https://arxiv.org/abs/2203.02155
Single-task fine-tuning: The pre-trained model is honed for a narrow and specific task such as toxicity detection or summarization, similar to BERT and T5.
Fine-tuning techniques: InstructGPT, LorA, QLorA
🚧 WIP - Caching
https://github.com/zilliztech/GPTCache
Redis LLM caching example https://www.youtube.com/watch?v=9VgpXcfJYvw&t=1517s
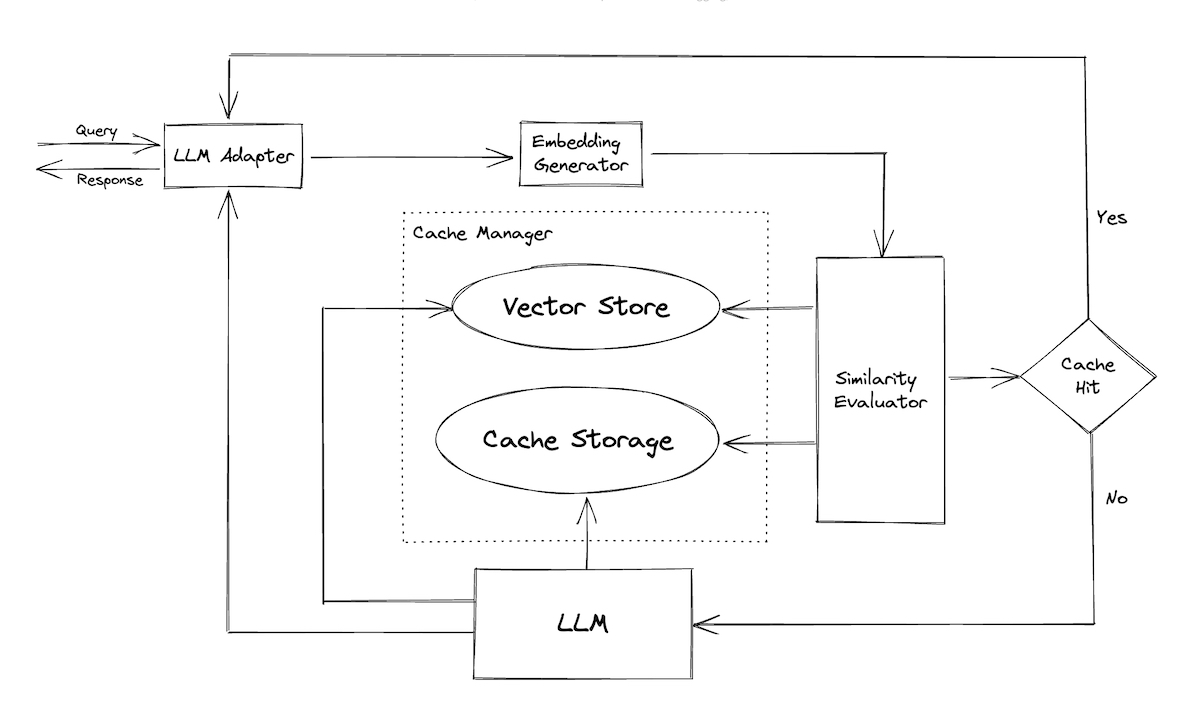 Image source: https://github.com/zilliztech/GPTCache
Image source: https://github.com/zilliztech/GPTCache
Quality Control LLMs
Guardrails
Pydantic style structural, type, and quality requirements on LLM outputs. If the check fails, it can trigger corrective action such as:
- filtering
- regenerating another response.
Supported validators
- Single output value validation:
- output is one of the predefined choices
- has a length within a certain range
- if numeric, falls within an expected range
- is a complete sentence.
- Syntactic checks:
- ensure that generated URLs are valid and reachable
- Python and SQL code is bug-free.
- Semantic checks: output is aligned with the reference document, or that the extractive summary closely matches the source document via cosine similarity or fuzzy matching
- Safety checks: output is free of inappropriate language or that the quality of translated text is high
NeMo-Guardrails
Semantic guardrails using LLMs
- Topical Rails: The core of the example is designed around
ensuring the bot doesn’t deviate from a specified topic of
conversation. This example covers: - Writing basic flows and
messages - Covers querying and using a Knowledge Base - Labels:
Topical;good first example- Link to example - Factual QA: The example largely focuses on two key aspects -
ensuring that the bot’s response is accurate and mitigates
hallucination issues. This example: - Covers querying and using a
Knowledge Base - Ensures answers are factual - Reduces hallucination
risks - Labels:
Topical- Link to example - Moderating Bots: Moderation is a complex, multi-pronged approach
task. In this example, we cover: - Ensuring Ethical Responses -
Blocking restricted words - “2 Strikes” ~ shutting down a
conversation with a hostile user. - Labels:
Safety;Security; - Link to example - Detect Jailbreaking Attempts: Malicious actors will attempt to
overwrite a bot’s safety features. This example: - Adds jailbreak
check on user’s input - Labels:
Security- Link to example - Safe Execution: LLMs are versatile but some problems are better
solved by using pre-existing solutions. For instance, if
Wolfram|Alpha is great at solving a mathematical problem, it is
better to use it to solve mathematical questions. That said, some
security concerns also need to be addressed, given that we are
enabling the LLM to execute custom code or a third-party service.
This example: - Walks through some security guideline - Showcases
execution for a third-party service - Labels:
Security- Link to example
Guidance
Domain-specific language for LLM interactions and output, 😢 no support for GPT4
Good option for open source models probably
Unlike Guardrails which imposes JSON schema via a prompt, Guidance enforces the schema by injecting tokens that make up the structure.
Guidance can:
- generate JSON that’s always valid
- generate complex output formats with multiple keys
- ensure that LLMs play the right roles
- agents interact with each other.
They also introduced a concept called token healing
How to apply guardrails?
Structural Guidance: Apply guidance whenever possible. It provides direct control over outputs and offers a more precise method to ensure that output conforms to a specific format
Syntactic guardrails: Syntax validation, such as type validation (is this a number?), range validation (are the values within a range of values), JSON validation (is this valid JSON?)
Content safety guardrails: These verify that the output has no harmful or inappropriate content. You can use a vocabulary look up such as checking the List of Dirty, Naughty, Obscene, and Otherwise Bad Words or using profanity detection models. (It’s common to run moderation classifiers on output.) More complex and nuanced output can rely on an LLM evaluator.
Semantic/factuality guardrails: These confirm that the output is semantically relevant to the input. Say we’re generating a two-sentence summary of a movie based on its synopsis. We can validate if the produced summary is semantically similar to the output, or have (another) LLM ascertain if the summary accurately represents the provided synopsis.
Input guardrails: Input sanitation layer, reducing the risk of inappropriate or adverserial prompts. For example, you’ll get an error if you ask Midjourney to generate NSFW content. Can be done comparing against a list of strings or using a moderation classifier.
Defensive UX
- set the right expectations -> add disclaimer to AI content, make data protection and privacy clear to end users
- enable efficient dismissal -> AI shouldn’t frustrate or block
- provide attribution -> highlighting where suggestions come from
- anchor on familiarity -> click on text more familiar than chatbots
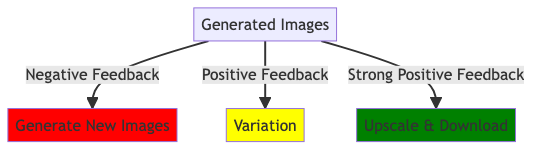
Collect user feedback
- Implicit: daily use metrics
- Explicit: thumbs up, thumbs down of AI respone