
This is my summary of the talk RAG for a medical company: the technical and product challenges by Noe Achache delivered at PyData Berlin 2024.
Product background
In France during the average GP visit the patient spends 15 minutes with the doctor. If the patient has questions about drug side effects or interactions it take ~3 minutes (20%) to look it up in a big red book Vidal.
Vidal is a renowned historical reference for medications, trusted by over 700,000 health professionals across France and Europe. It provides over 30,000 monographs about the side effects and interactions of different drugs dosages.
Product Discovery questions
To build a valuable product for the doctors, look at the following questions:
| Value | Does the doctor perceive the benefit in using it? |
|---|---|
| Usability | Will doctors be able to use it? |
| Feasibility | Can we build and maintain this product? |
| Viability | Is this solution viable from a business standpoint? |
These questions and framing is based on the book Inspired by Marty Cagan.
Focusing on usability, the goal is to make the solution work for doctors.
Assumptions:
- AI never 100% reliable → cite sources
- doctors only trust reliable sources → display source and quote in the response
Solution
Here’s an example of the doctor interacting with the system:
- Question: How long should I take 💊 Eliquis?
- Rephrase question: How long should I take Eliquis?
- Highlight documents with hits, which can be manually selected:
- Eliquis 5 mg dosage
- Aspirin
- etc.
-
Return extractive answer from source document
GPT 4 answer: Take Eliquis every hour for 12 hours.
Relevant source:
“Eliquis is a common treatment for malaria.
Eliquis 5 mg should be taken once an hour for 12 hours.”
Initial approach
❌ Initial approach was just use ChatGPT, this failed due to no source.
Medical advice is high trust, sources are a must!
Evaluating the solution
🩺 User interviews dug into what searches doctors have done in the last week?
They then sourced a 100 questions from doctors based on their searches in the last week. This 100 question dataset was the core evaluation set.
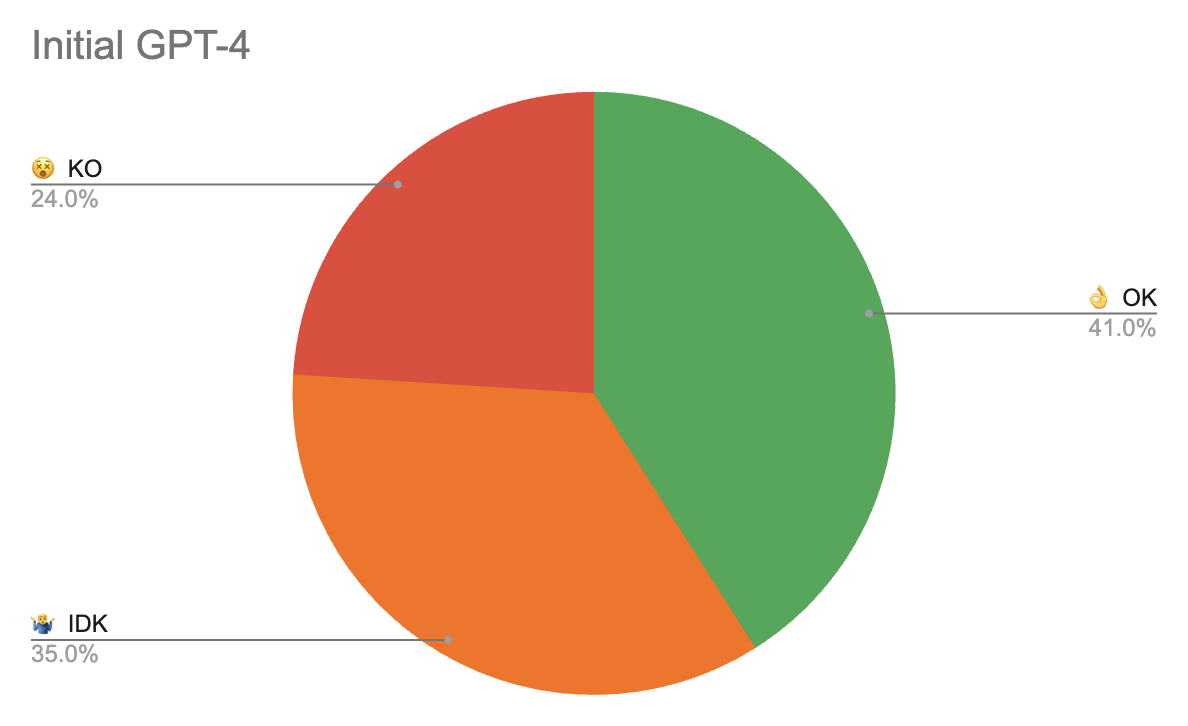
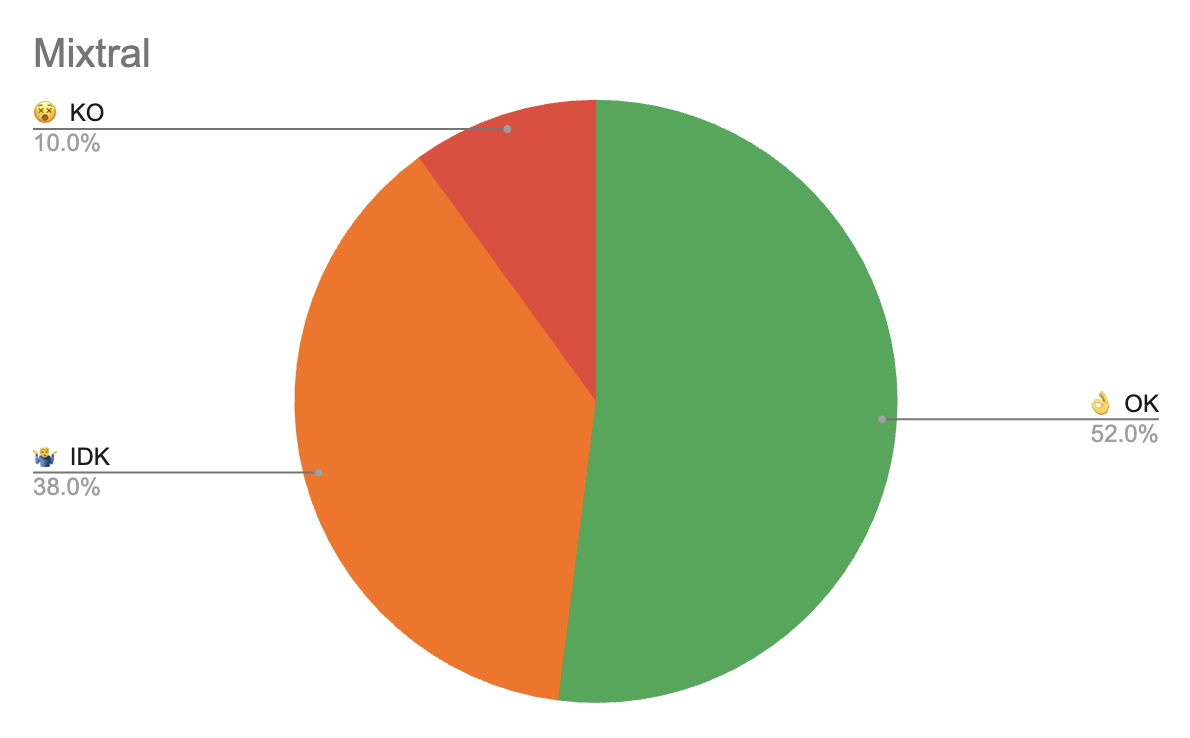
The initial approach, chainlit for UI with a default langchain RAG with text splitter chunking texts into 8K character chunks with 100 character overlaps, performed poorly on the evaluation data set:
👌 OK - answer accepted by doctor
🤷♂️ IDK - I don’t know, answer where the model is uncertain in its answer
😵 KO - knocked out, answer is wrong
Chunking challenges
The approach of chunking 8K tokens into one vector is like using an axe to slice fruits into small pieces.
The pieces of fruit (vector embeddings) you get are too big and often mixed together which means it’s harder to find the fruit you are looking for (query vector).
The solution was moving to smaller chunk vectros. Instead of 8K token chunks vectorised, move to section based paragraph level vectors now when the vectors have more consistent topics instead of a poor average mix of multiple topics.
This led to a substantial improvement in performance:
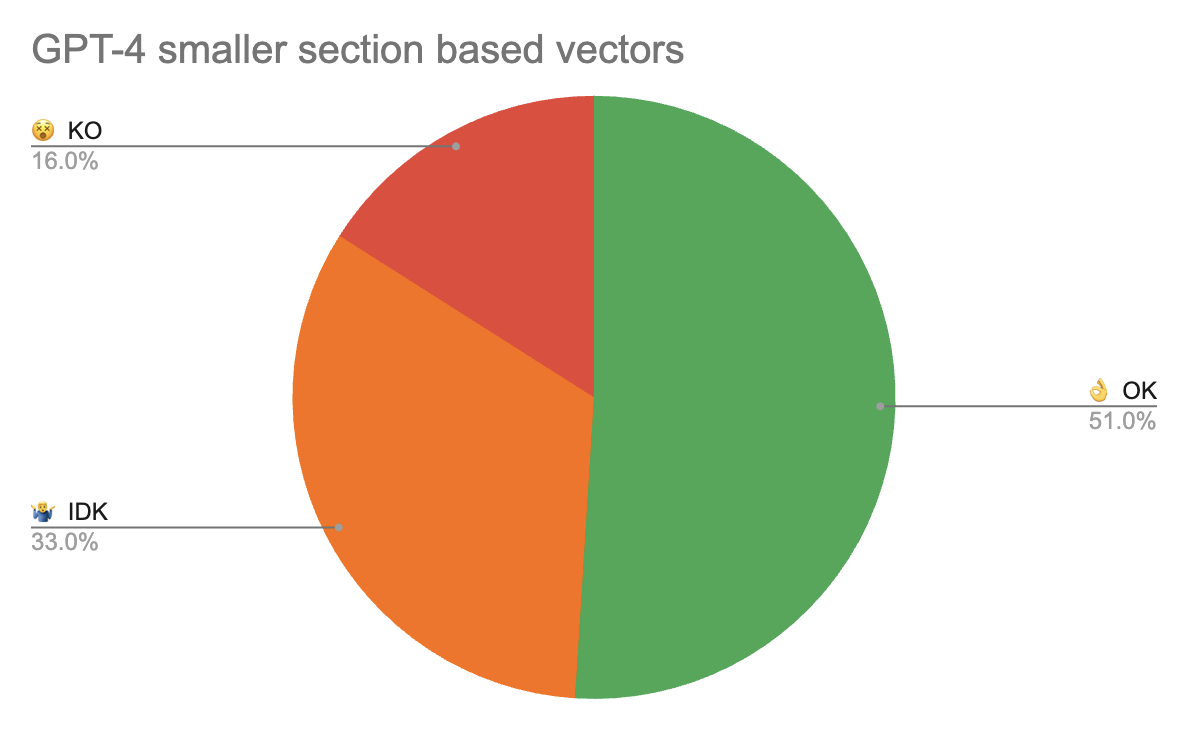
Performance was still not good enough, how to reduce the red slice of the pie?
The chainlit chat interface has a prompt playground where users can tweak and rerun prompts.
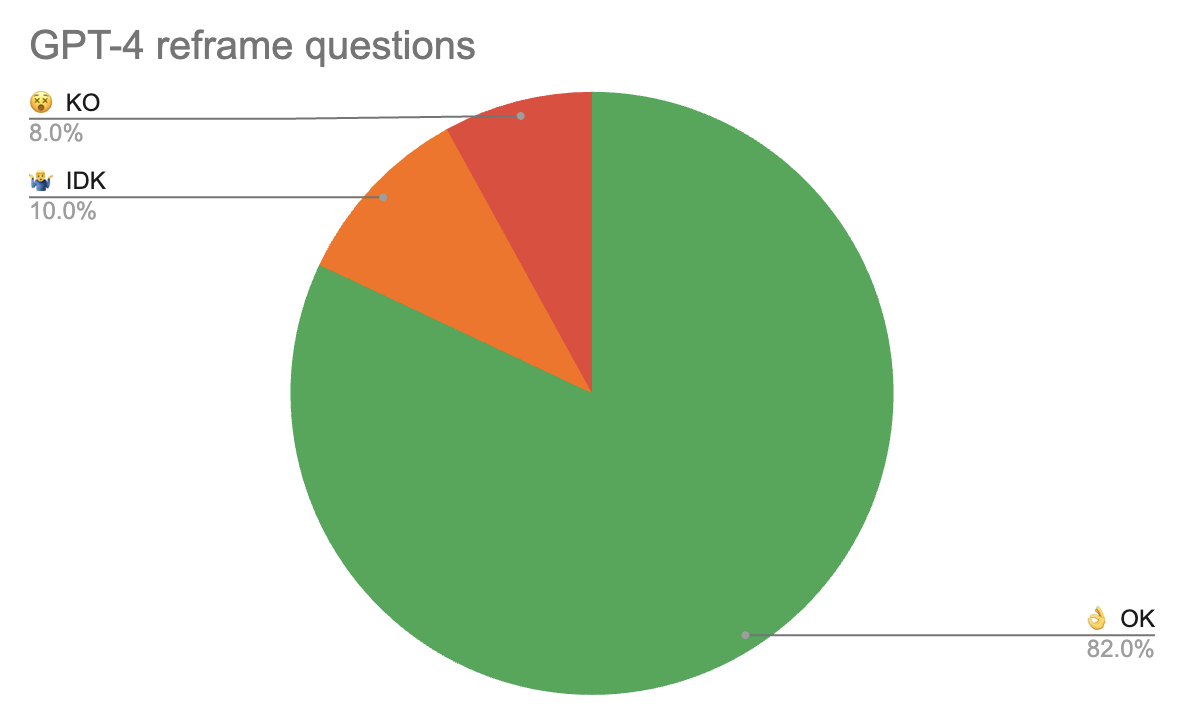
A business stakeholder looking at the prompt results in the playground had an idea: Include the International Nonproprietary Name (INN) of the drugs as well This allowed finding generic and molecule names with the same vector as the INN.
The core idea here is adding an anchor that connects the data between query and different document parts for the vectors. Instead of using an API to link to the INN id, they just used ChatGPT to generate it for quick prototyping.
This was a huge improvement:
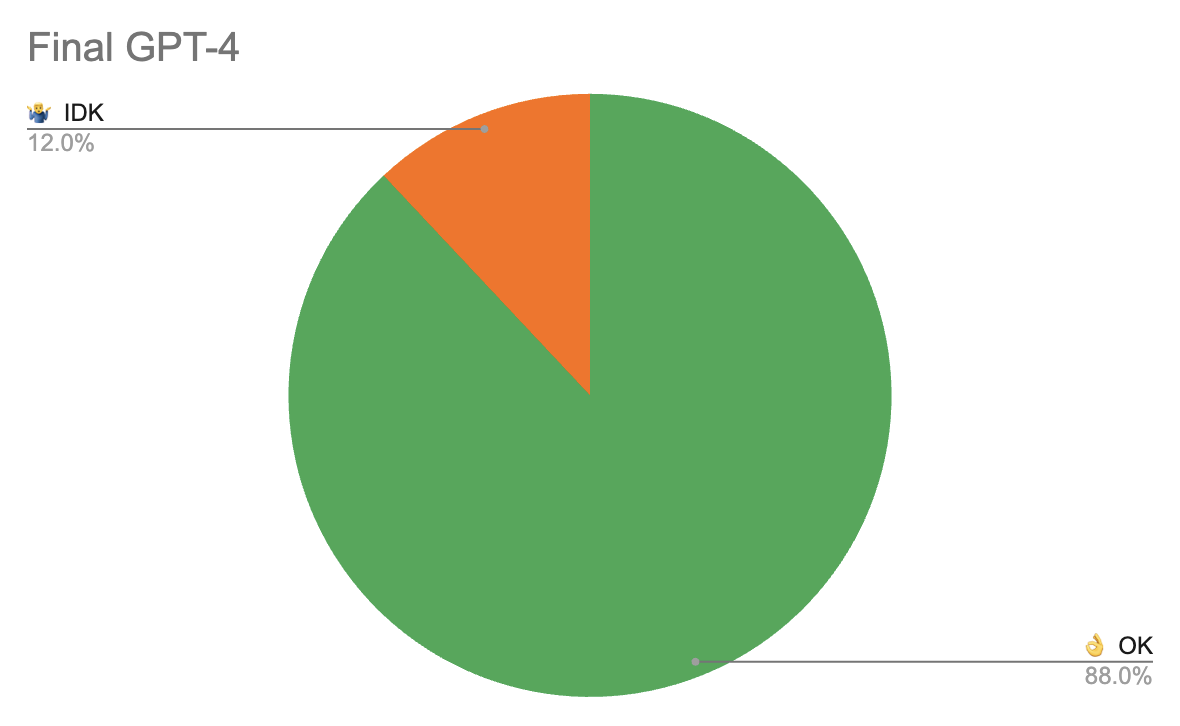
Finally tweaking the prompts a bit more led to no wrong answers:
This is the arch of the final solution:
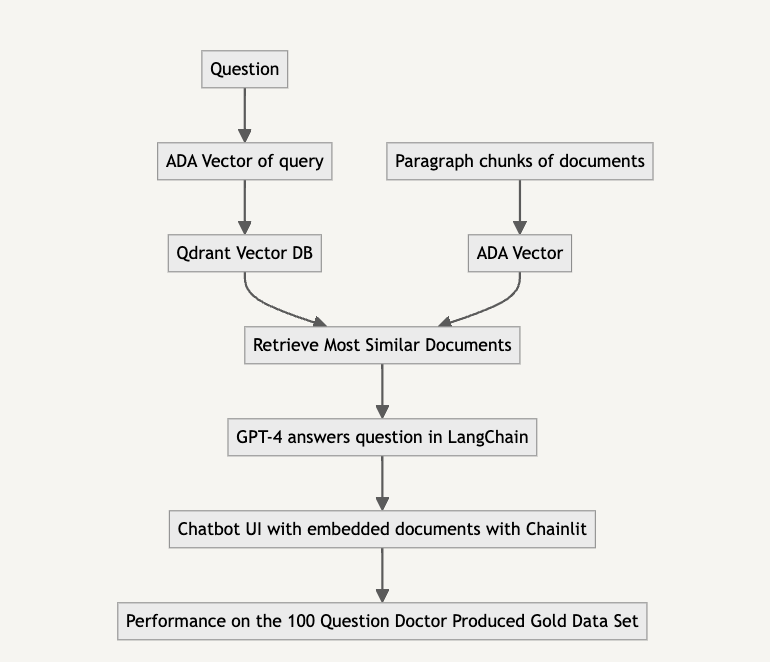
Trying Mixtral vs GPT
😢 Trying the state of the art open source LLM at time of development, Mixtral led to poor performance. Hopefully Llama 3 would perform better!
Architecture notes
Chat interface implemented with Chainlit for quick chatbot UI prototype.
Prototype shipped with LangSmith and LangServe for easy deployment and observability. Currently I have very similar telemery capabilities to Langsmith with honeycomb.
💡 Langsmith also has a prompt playground feature with 1 click prompt playground exports of prompts. This is a good idea to add to honeycomb.
Improvement opportunities
Some usability learnings, discovered during development:
How does the tool choose the docs? Empower users to select them → make them selectable
Monographs are too long, users can’t see where the info comes from → highlight source section
Open usability challenges
- Oh I need to ask a question?
- Dr feels attacked by rephrasing the question -> Is my question not good enough?
Need more automatic evaluations:
- hit rate, of retrieval based on tracking doctor user behaviour on Vidal website
- Auto score with LLM as a judge, could use ragas for this.